
業務の中でリサーチや、他社の分析を行う際に、Google検索は真っ先に利用する手段です。しかし膨大な検索結果の中から必要な情報を抽出し、それを効率的に分析するための手段は限られています。そこで活躍するのがAIツール「Dify」です。本記事では、Difyのフローの中でGoogleのCustomSearchJsonAPIを活用して、検索結果データをLLMに読み込ませることで、活用・分析する手法を解説します。
事前準備
GoogleのCustom Search JSON APIを利用する
今回使用するのは以下のサービスです。
ページの中段からAPIキーを発行します。
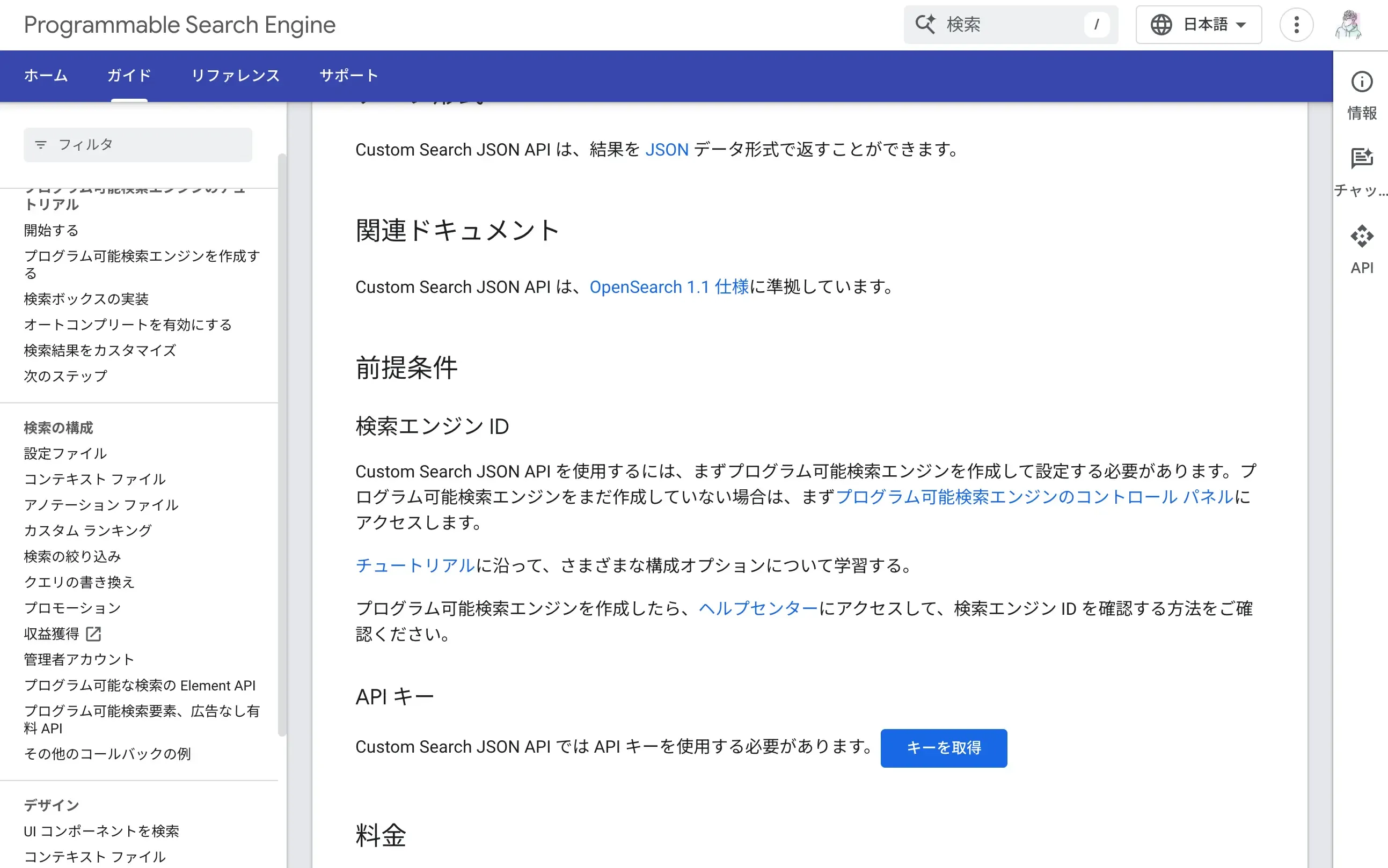
“キーを取得ボタン”を押すとGoogleCloudConsoleのプロジェクトを作成します。今回はdify-localという名前にしました。利用規約に同意してNEXTボタンを押します。
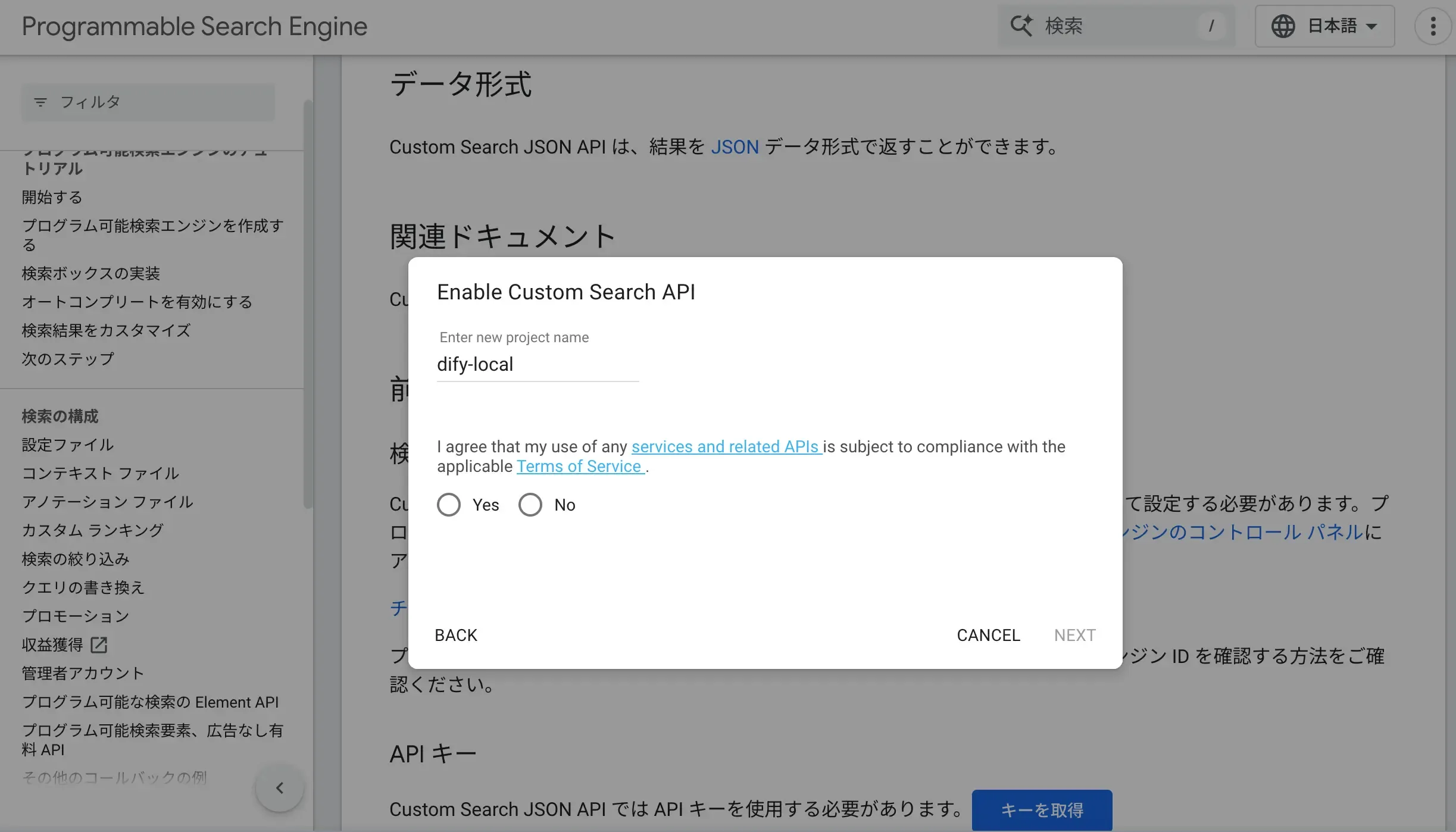
次にAPIKeyが発行されます。このタイミングでメモしなくても後ほどGoogleCloudの認証情報からAPIKeyは参照可能です。
次にAPI Consoleをクリックします。
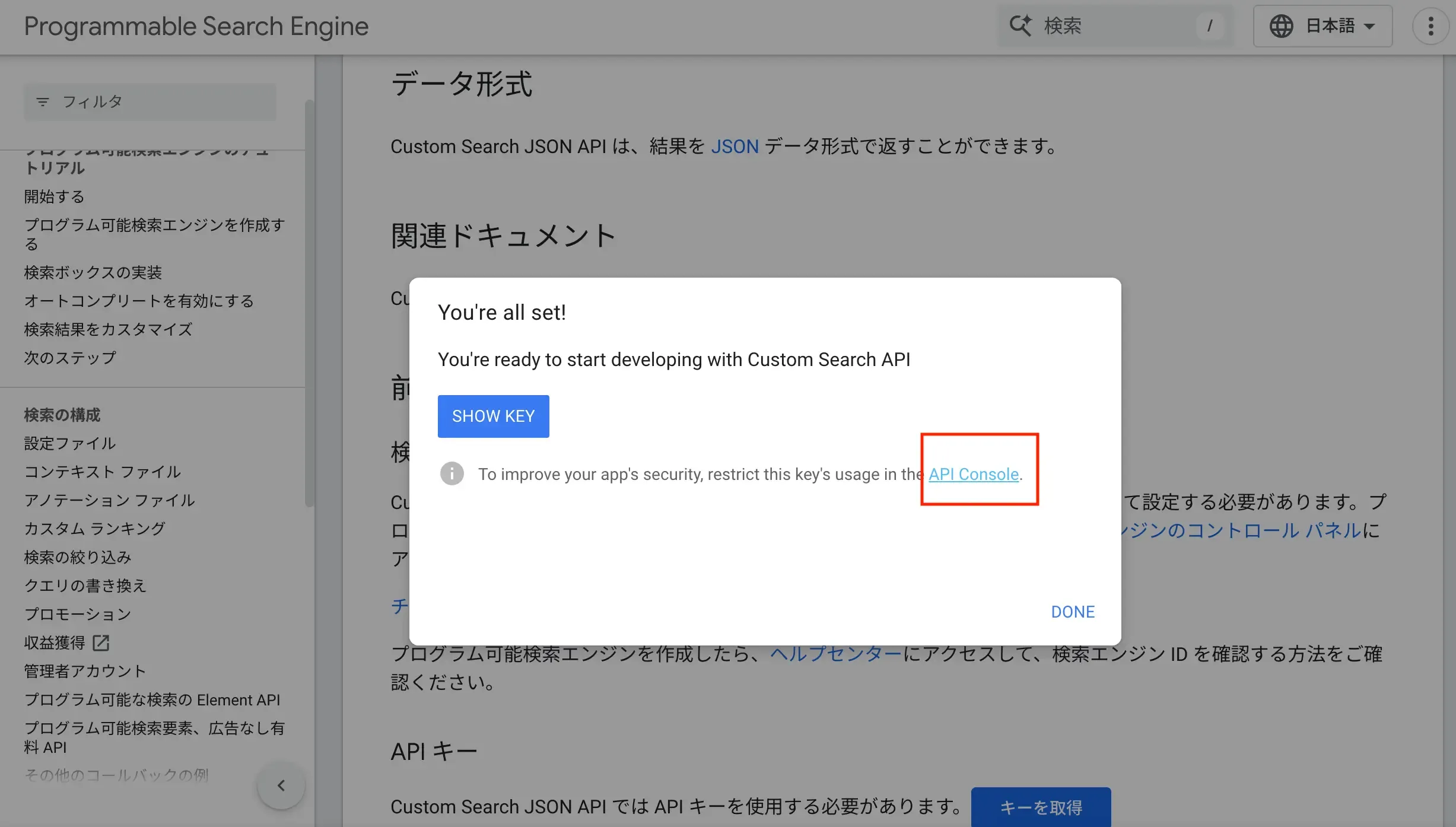
ここで発行されたAPIを編集しておきましょう。セキュリティ観点でAPIを使用できるIPアドレスを制限しておきます。API Keyをメモしておきましょう。
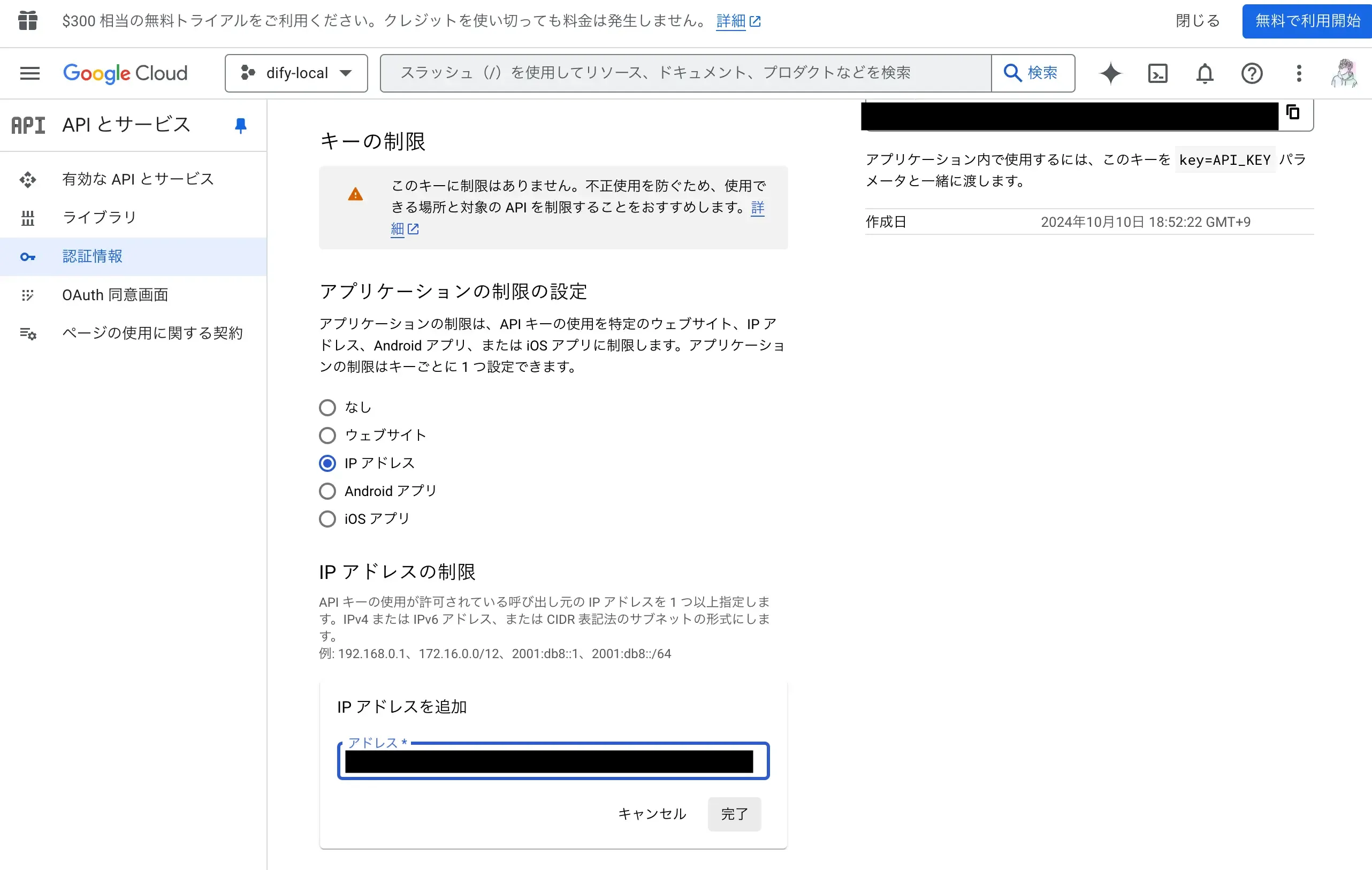
次に検索エンジンを追加しましょう。
下記のURLにアクセスします。
Programmable Search Engine
右上の”追加”をクリックします。
検索エンジン名を設定し、”作成”を押します。
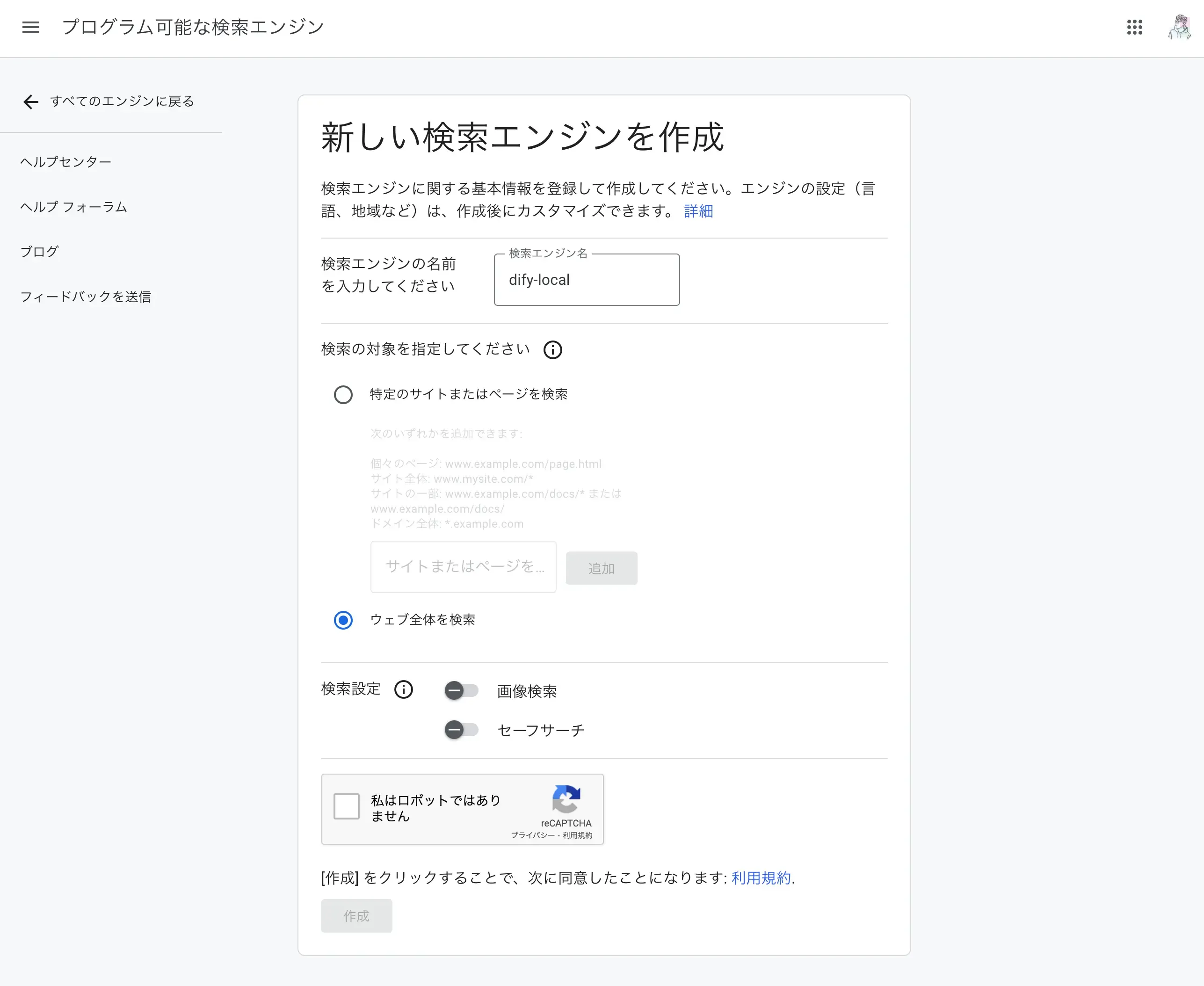
検索エンジン一覧に戻り作成した検索エンジンを確認します。
中段に記載されている検索エンジンIDは後ほど使うのでメモしておきましょう。
ここまででCustom Search JSON APIを利用する準備が整いました。
(補足)Custom Search JSON APIの料金
1日100件まで無料なので個人利用なら十分ですね。
Custom Search JSON API では、1 日あたり 100 件の検索クエリを無料で利用できます。これを超えて必要な場合は、API Console でbillingをお申し込みいただけます。追加リクエストの料金は、クエリ 1, 000 クエリあたり $5 で、1 日あたり 1 万クエリまでです。
Difyでワークフローを作成する
まず初めに、最初から作成をクリックします。
今回はチャットボット+Chatflowを選択し、名前をつけて作成します。
.webp&w=3840&q=75)
ワークフロー雛形を作成する
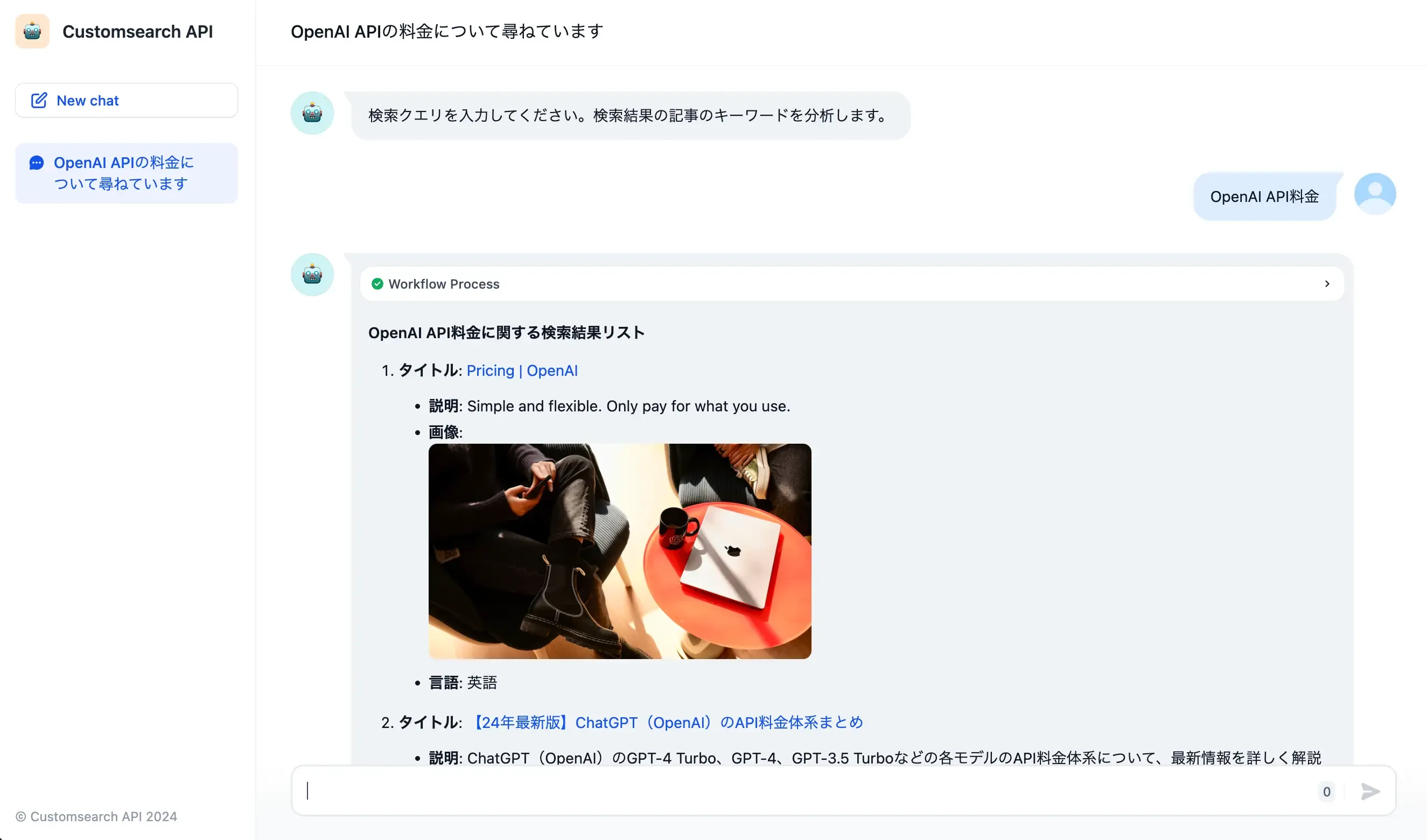
今回は、ユーザーがキーワードを入力すると、そのキーワードの検索結果をLLMで分析し、タイトルやディスクリプションからキーワードを抜き出すツールを作ります。
ワークフロー画面に入り、開始ブロックとLLMブロックの間に、Custom Search JSON APIを呼び出すブロックを作ります。
HTTPリクエストブロックを作成する
ブロックの選択肢からHTTPリクエストを選択します。
Google Custom Search APIのエンドポイントは以下の通りです。
https://www.googleapis.com/customsearch/v1
APIをGETメソッドに変更し、上記のURLを入力します。
ヘッダーへの設定内容
キー | 値 |
|---|---|
Content-Type | application/json |
Accept-Language | ja-JP |
パラメータへの設定内容
キー | 値 |
|---|---|
key | 先ほど取得したAPIKey |
cx | 先ほど取得した検索エンジンID |
q | テストの検索クエリ(後ほど変更します。) |
num | 検索結果の取得件数 |
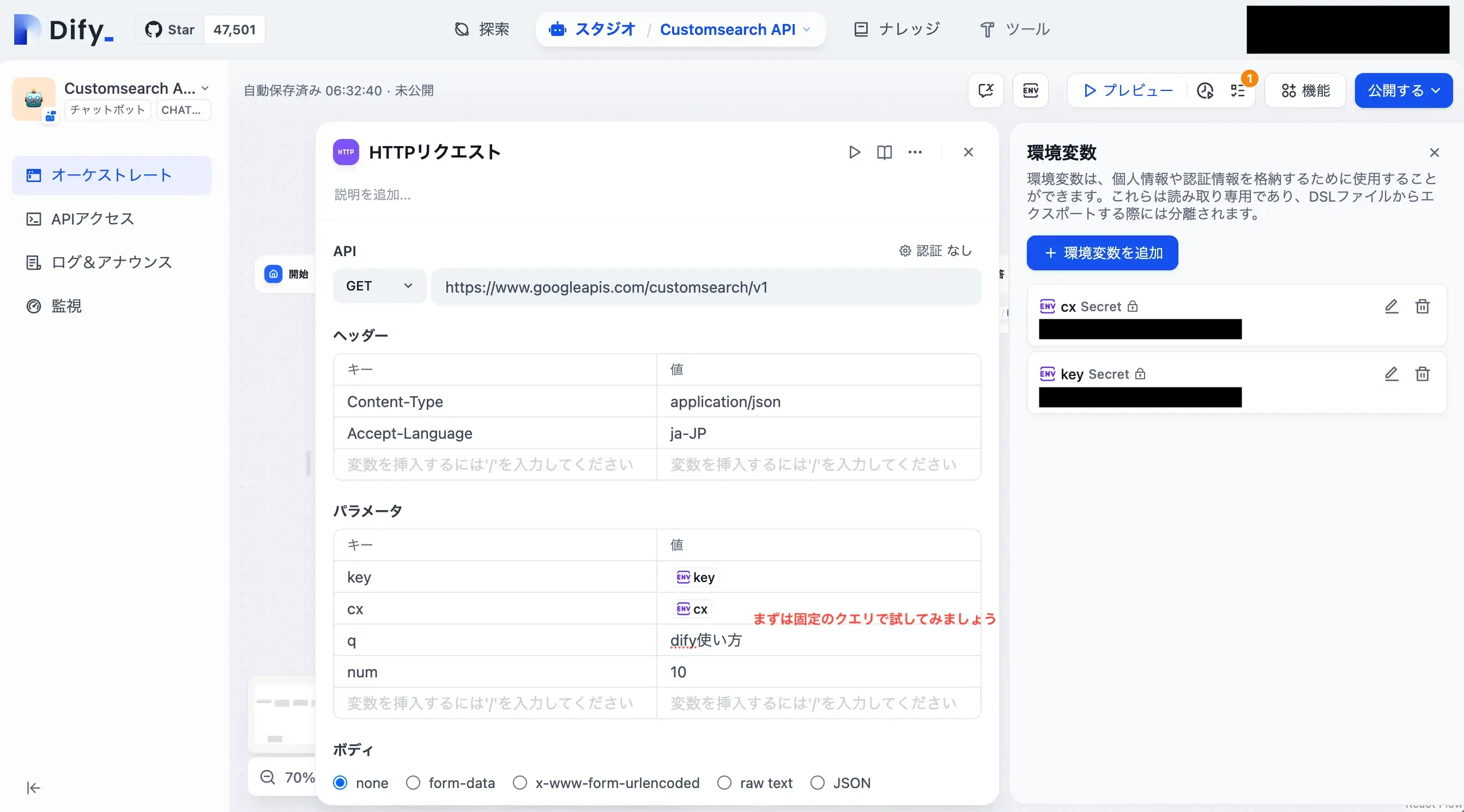
今回の場合は、keyとcxは環境変数に保存しています。このワークフローをDSLファイルなどで共有する予定がある場合は、APIkeyなどをファイルに含めない形で共有できます。
準備が整ったので、HTTPリクエストの右側にある再生ボタンをクリックします。
取得できていますね。
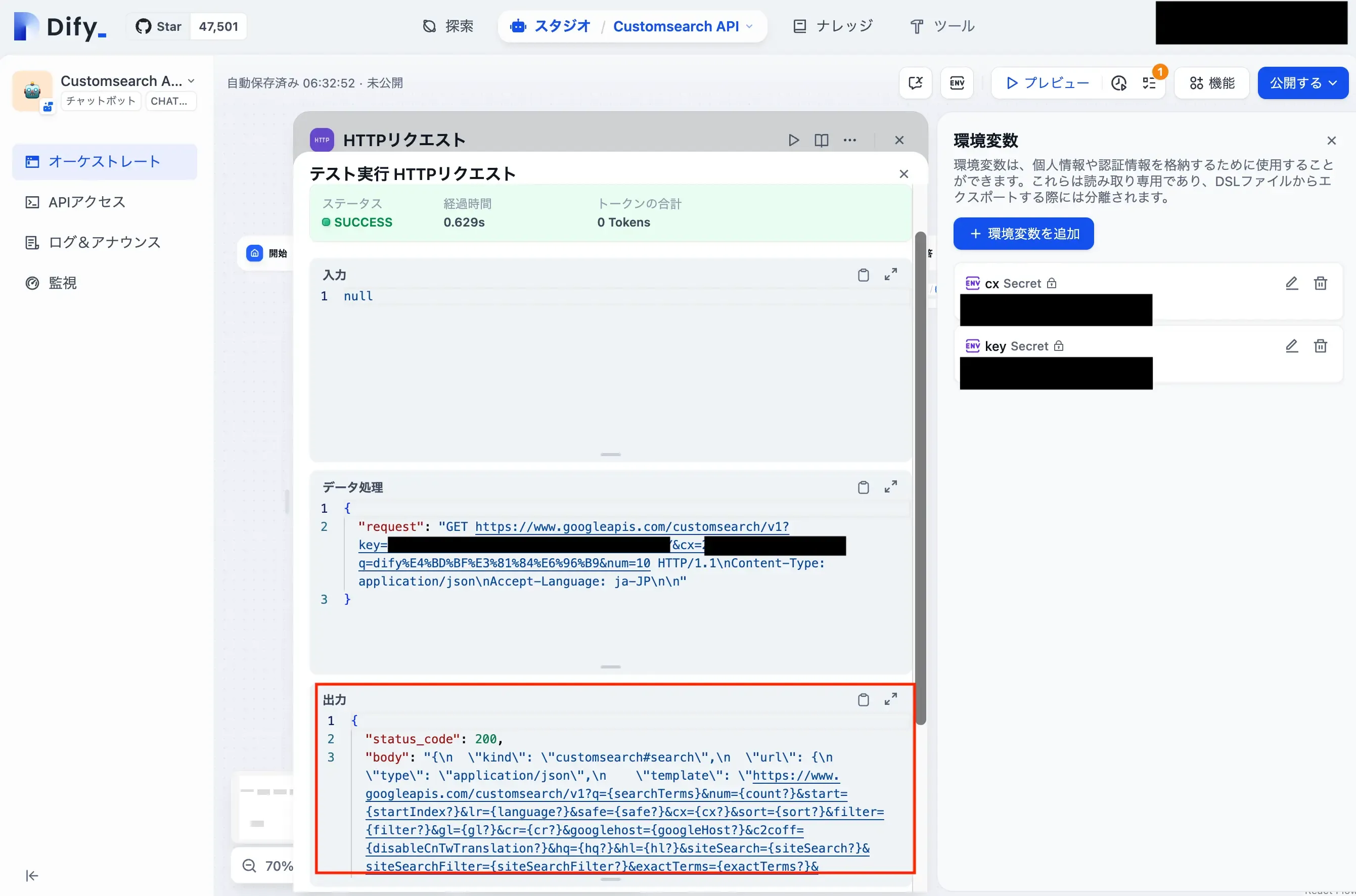
取得確認ができたのち、ユーザーの入力によって検索クエリは変えたいので、クエリパラメータは、テスト時に設定したクエリから、{{#sys.query#}}に変えておきましょう。
HTTPリクエストブロックで取得した情報を成形する
LLMとHTTPリクエストブロックの間に新たにコードブロックを追加します。
ここではHTTPリクエストで取得した情報には無駄なステータス情報や実行時間などのデータが含まれるため、後のLLMへのトークン数を節約し、回答精度を上げるために、綺麗にします。
データ形式による精度への影響
- JSON形式: データが構造化されているため、モデルがそれぞれの要素をより簡単に解釈できる場合があります。特にデータの意味や属性が明確であれば、精度が向上することがあります。
- 文字列(string)形式: データが一連の文字列として渡される場合、文脈や関係性が曖昧になることがあります。これは、モデルが情報を誤解するリスクを高めることがあるため、精度に悪影響を与えることもあります。
データ形式によるコストへの影響
- JSON形式: JSONはキーと値のペアが構造的に整理されているため、キー部分が追加のトークンを消費します。例えば、キー名が長いほどトークン数が増えます。そのため、特にキーが冗長な場合、トークンコストが増加する可能性があります。
- 文字列(string)形式: 構造がなく、シンプルに情報を詰め込む場合、JSONよりもトークンコストを抑えることができる場合があります。しかし、情報の意味が曖昧になる可能性があり、コンテキストが不足するとモデルが誤解するリスクが増します。
- その他の形式: MarkdownやXMLのようなフォーマットも使用可能ですが、これらも同様にタグやマークアップがトークンとしてカウントされるため、トークンコストが増える可能性があります。
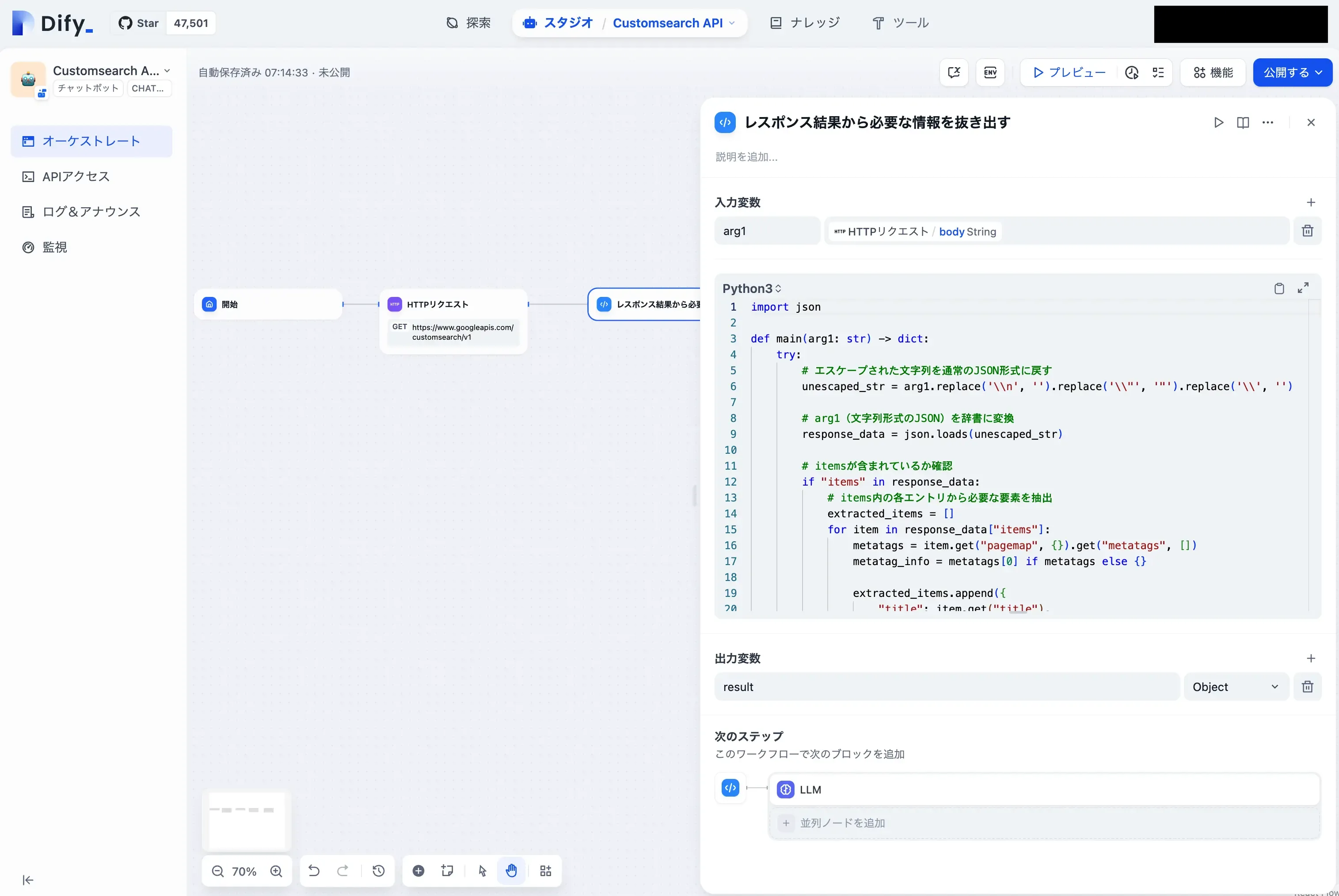
入力変数を以下のように入力します。
引数 | {x} 変数を設定 |
|---|---|
arg1 | HTTPリクエスト / body String |
コード記入部分に以下のコードを書きます。今回はJSON形式でLLMに渡してあげる形にしています。
1import json
2
3def main(arg1: str) -> dict:
4 try:
5 # エスケープされた文字列を通常のJSON形式に戻す
6 unescaped_str = arg1.replace('\\n', '').replace('\\"', '"').replace('\\', '')
7
8 # arg1(文字列形式のJSON)を辞書に変換
9 response_data = json.loads(unescaped_str)
10
11 # itemsが含まれているか確認
12 if "items" in response_data:
13 # items内の各エントリから必要な要素を抽出
14 extracted_items = []
15 for item in response_data["items"]:
16 metatags = item.get("pagemap", {}).get("metatags", [])
17 metatag_info = metatags[0] if metatags else {}
18
19 extracted_items.append({
20 "title": item.get("title"),
21 "link": item.get("link"),
22 "metatags": metatag_info
23 })
24
25 # リストを辞書内に格納して返す
26 return {"result": {"items": extracted_items}}
27 else:
28 return {"result": {"error": "No 'items' found in the response"}}
29
30 except json.JSONDecodeError as e:
31 return {"result": {"error": f"JSONDecodeError: {str(e)}"}}最後に出力変数をObjectとしておきます。
LLMブロックを作成する
LLMブロックのプロンプトを書いていきましょう
今回はテストなのでgpt-4o-miniを使っていきます。
項目 | 入力内容 |
|---|---|
モデル | gpt-4o-mini |
コンテキスト | 空欄(*1) |
SYSTEM | {直前のコードブロックのアウトプット}の内容をリストに整理してアウトプットしたのち、{{#sys.query#}}の検索結果の記事のキーワードについて分析してください。 |
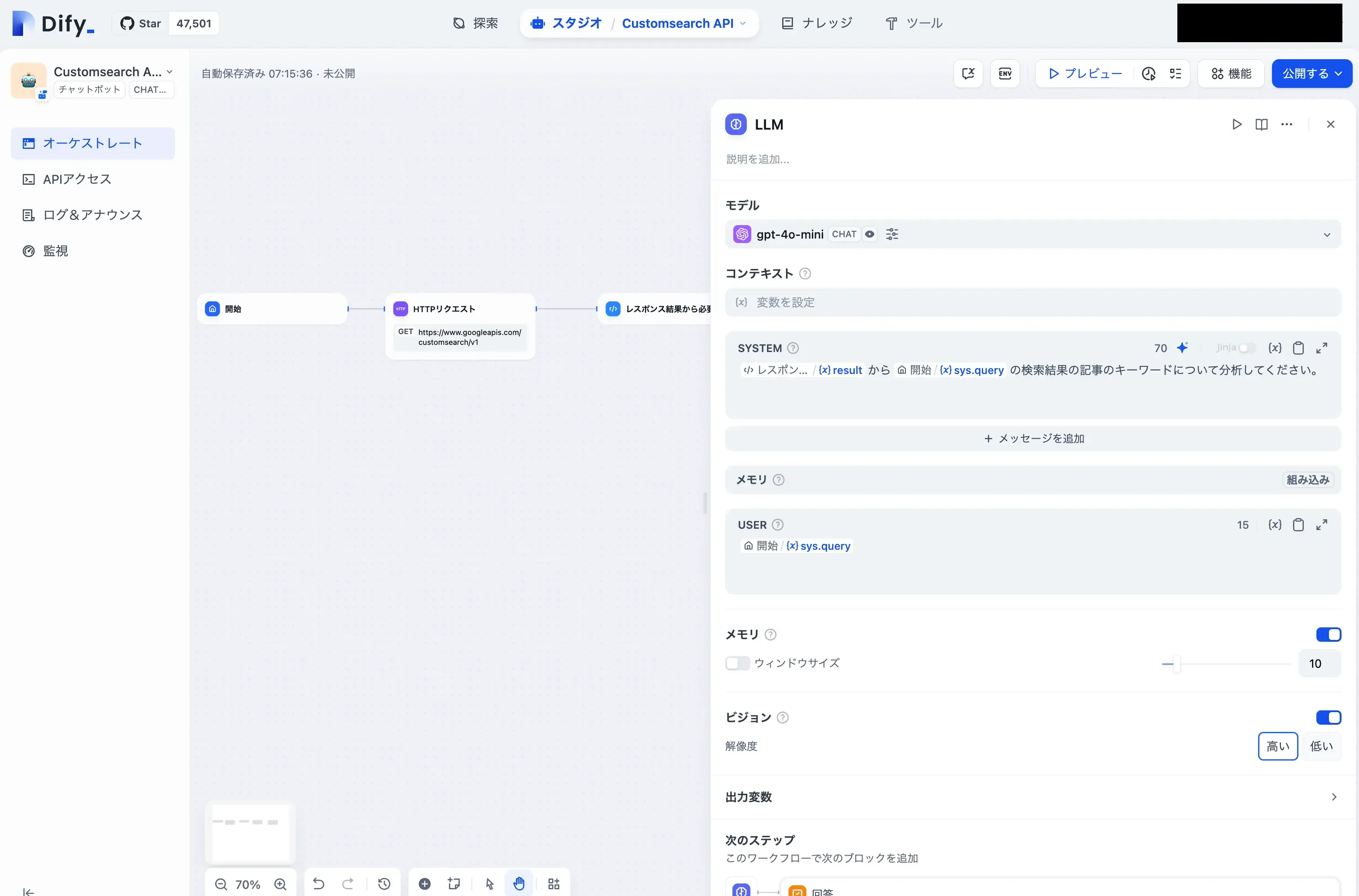
回答ブロック
LLMの結果が出力されるようになっているか確認しましょう。なっていればそのままで大丈夫です。
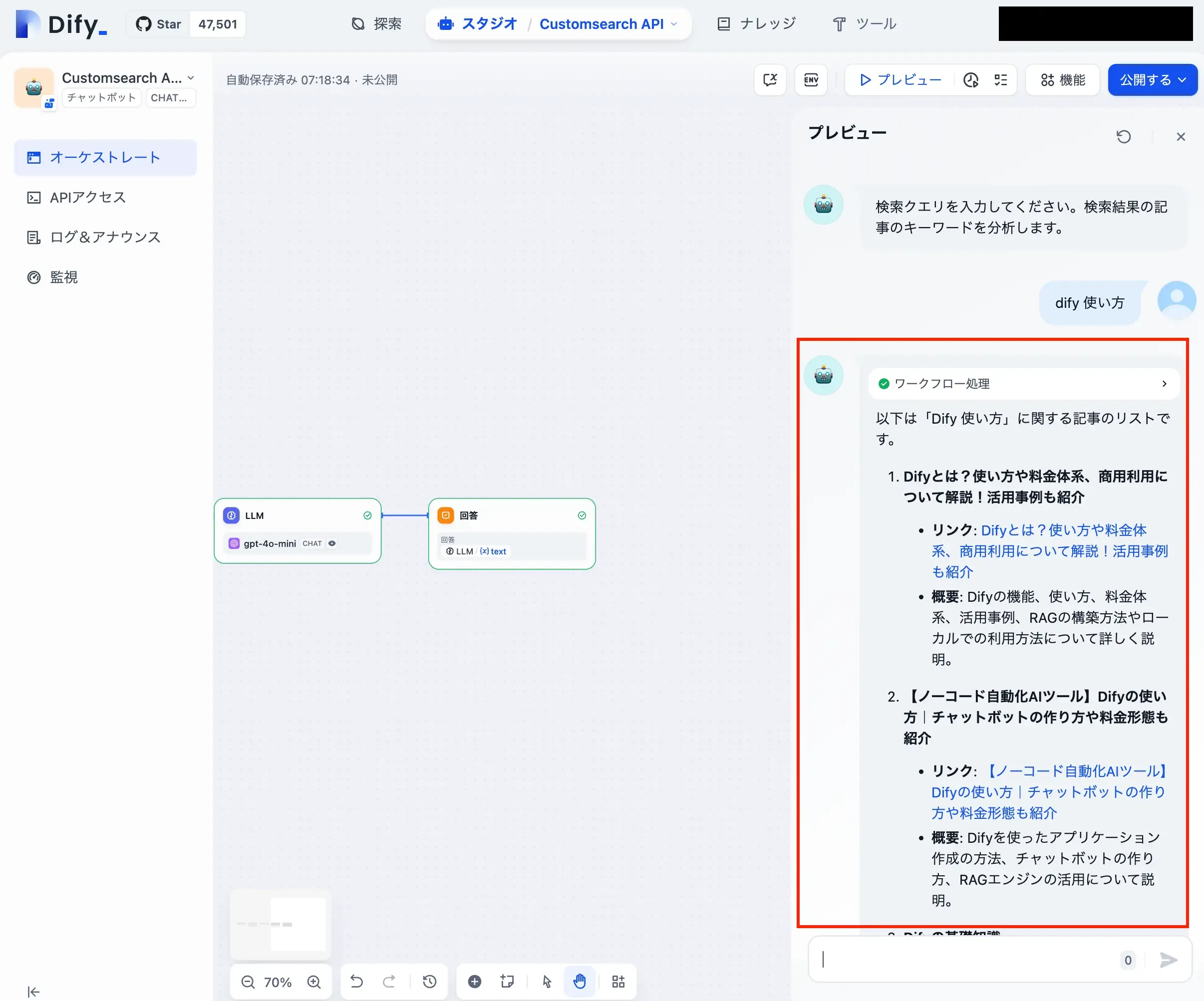
プレビューで確認
以下のようにプレビューで問題なく動けば、テストは完了です。
実際のアプリケーションを使ってみる
画面右上の”公開する”というボタンから、”更新”を押下し,
その後保存が確認できたら”アプリを実行”を押しましょう。
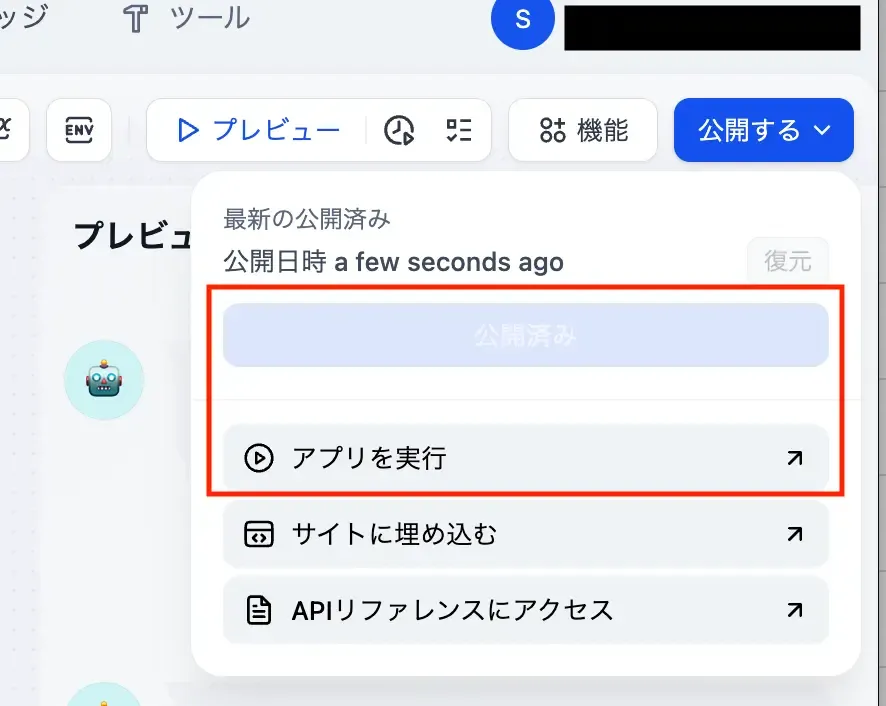
下記のような画面が開くので適当な検索クエリを投げてみます。
きちんと応答されています。
応用編
取得URLの遷移先を分析する
今回のアプリではタイトルやリンクなどは取得できますが、クリックし先のページの情報が取得できません。その場合はFireCrawlなどの拡張ツールを活用して、取得した検索結果のURLをさらに処理することで検索結果とその先のページの内容から、SEO分析なども可能です。
これができれば、企業リサーチなどでも、使えそうですね。
検索クエリをLLMに処理させる
今回のアプリでは、検索クエリのみユーザーが入力する形になっていますが、HTTPリクエストブロックの前にLLMブロックを作成することで、文章などでユーザーが投げかけた時に検索クエリを出力し、それをリクエストするということもできます。この実装をすることでユーザーは質問をするだけで良いので、UXが向上します。
まとめ
いかがでしたでしょうか?日常の業務で意外と時間を取られている検索やリサーチ、ドキュメント作成などはDifyを使うことで圧倒的に効率化することが可能です。
追加のカスタマイズもシリーズ形式で上げていこうと思いますので、皆様の参考になれば幸いです。
弊社では、生成AI使い方がわからない、Dify使ってみたけど思うようにうまくいかない、そんな方にDifyのセットアップやワークフロー構築などの支援が可能です。ご興味をお持ちいただければ問い合わせよりお気軽にご相談お待ちしております。


.webp&w=640&q=75)